در اولین کنفرانس LlamaCon، متا امروز چندین اعلان مهم داشت و ابزارهایی را معرفی کرد تا خانواده مدلهای Llama را برای توسعهدهندگان در دسترستر کند. مهمترین بخش این رویداد، راهاندازی Llama API بود که اکنون به صورت پیشنمایش رایگان محدود برای توسعهدهندگان در دسترس است.
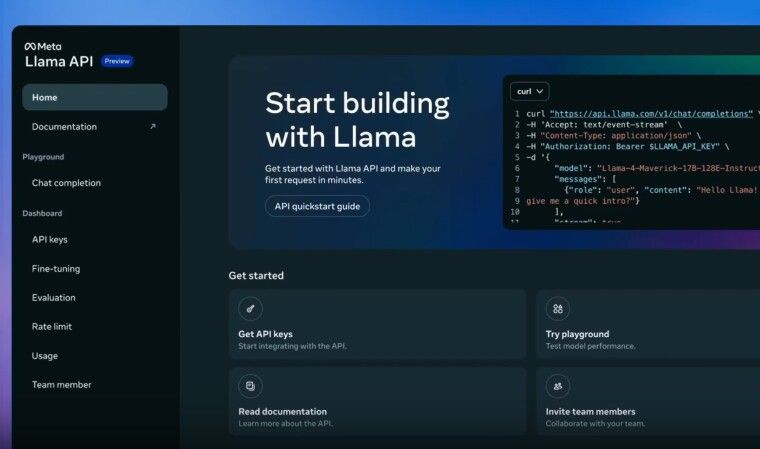
Llama API به توسعهدهندگان اجازه میدهد مدلهای مختلف Llama را آزمایش کنند، از جمله مدلهای تازه معرفی شده Llama 4 Scout و Llama 4 Maverick. این API امکان ایجاد کلید API با یک کلیک و SDKهای سبک TypeScript و Python را ارائه میدهد. برای راحتی توسعهدهندگان در انتقال برنامههای مبتنی بر OpenAI، Llama API با SDK اپنایآی سازگار است.
متا همچنین با Cerebras و Groq همکاری میکند تا سرعتهای استنتاج سریعتری را برای Llama API ارائه دهد. Cerebras ادعا میکند که مدل Llama 4 Cerebras در API میتواند سرعت تولید توکن را تا 18 برابر سریعتر از راهحلهای معمولی مبتنی بر GPU از NVIDIA و دیگران ارائه دهد. طبق سایت بنچمارک Artificial Analysis، راهحل Cerebras برای Llama 4 Scout بیش از 2,600 توکن در ثانیه را ارائه داد، در مقایسه با ChatGPT که 130 توکن در ثانیه و DeepSeek که 25 توکن در ثانیه ارائه میدهند.
اندرو فلدمن، مدیرعامل و همبنیانگذار Cerebras، گفت: “Cerebras افتخار میکند که Llama API را به سریعترین API استنتاج در جهان تبدیل کرده است. توسعهدهندگانی که برنامههای عاملی و بلادرنگ میسازند به سرعت نیاز دارند. با Cerebras روی Llama API، آنها میتوانند سیستمهای هوش مصنوعی بسازند که اساساً برای ابرهای استنتاج مبتنی بر GPU پیشرو غیرقابل دسترس است.”
توسعهدهندگان علاقهمند میتوانند با انتخاب Cerebras از گزینههای مدل در Llama API به این استنتاج فوقالعاده سریع Llama 4 دسترسی پیدا کنند. Llama 4 Scout همچنین از طریق Groq در دسترس است، اما در حال حاضر با سرعت بیش از 460 توکن در ثانیه اجرا میشود که حدود 6 برابر کندتر از راهحل Cerebras است، اما همچنان 4 برابر سریعتر از راهحلهای مبتنی بر GPU دیگر است.
source